时序差分学习
时序差分学习(Temporal-Difference Learning)融合了蒙特卡洛(MC)和动态规划(DP)的思想:
- TD像MC那样直接从回合(episode)学习,不需要了解模型本身,是无模型方法;
- TD像DP那样基于已经学习过的状态估计新的状态,即引导(bootstrapping)。
总的来说,TD方法可以学习不完整的回合,通过自身的引导猜测回合的结果,同时持续更新这个猜测。
时序差分预测
时序差分预测的目标是在一个固定的策略 $\pi$ 下,从一系列不完整的回合中学习到该策略下的状态值函数 $v_\pi(s)$。
回顾值函数的展开:
在蒙特卡洛预测中,仅仅用到第一个等号,而在时序差分预测中,考虑第二个等号,采用的迭代式如下:
这里 $R_{t+1}+\gamma v(S_{t+1})$ 称为TD目标值,$\delta_t=R_{t+1}+\gamma v(S_{t+1})-v(S_t)$ 称为TD误差,将用TD目标值近似代替回报 $G_t$ 的过程称为引导(BootStrapping)。

TD与MC的区别
- TD不需要等到回合结束后才学习,他可以每一步后都更新;
- TD可以在没有终止状态的环境中学习。
另外,我们知道真实的TD目标值 $R_{t+1}+\gamma v_\pi(S_{t+1})$ 是对 $v_\pi(S_t)$ 的无偏估计,而TD目标值 $R_{t+1}+\gamma v(S_{t+1})$ 是有偏估计;进一步,它的方差比回报(无偏估计 $G_t$)的方差更小,这是因为TD目标值仅依赖于一个随机动作,而回报依赖诸多随机动作。
- MC没有偏差,但有着较高的方差,对初值不敏感;
- TD有较低的方差,但有一定程度的偏差,通常比MC更高效,但对初值敏感。
对于MC和TD谁学得更快这个问题目前尚未解决,从实践上看,TD学得更快。
MC算法试图收敛至一个最小化状态价值与实际回报的均方差的解,即
这个解能够很好的拟合观测到的回报。
TD算法则试图收敛至一个根据已有经验构建的最大似然马尔可夫模型的解,即首先根据已有经验估计状态间的转移概率
同时估计某一个状态的即时奖励
最后计算该MDP的状态值函数。
- MC方法的解对现有的数据表现得很好,它不利用马尔可夫性质,在非马尔可夫环境中更有效;
- TD方法的解对未来数据产生较小的误差,它利用马尔可夫性质,在马尔可夫环境中更有效。
$\pmb\lambda$ 时序差分学习
前面介绍的TD只走一步就进行了更新,称为一步TD或TD(0),而MC方法则需要回合走到终止状态才能更新。因此,一个折衷的方法就是走大于1,但小于整个回合步数的步数,这种方法相当于介于TD(0)和MC之间。
利用回报的公式,可以写出$n$步TD回报公式:
因此,基于此的值函数更新公式如下:
记备份(更新)量为 $\Delta_t(S_t)=\alpha\big(G_t^{(n)}-v_t(S_t)\big)$,于是
- 在线更新:每一个时间步更新一次价值函数,$v_{t+1}(s)\leftarrow v_t(s)+\Delta_t(s)$;
- 离线更新:一个回合只更新一次价值函数,$\displaystyle v(s)\leftarrow v(s)+\sum_{t=0}^{T-1}\Delta_t(s)$。

TD($\pmb\lambda$)
注意到对同一时间的回报,我们可以采用不同步数的结果进行平均,由此引入新的参数 $\lambda$,用以综合考虑所有步数的预测。
定义 $\lambda$-回报为
对应的 $\lambda$-预测写成 TD($\lambda$):
可以看到 TD(0) 就是之前介绍的时序差分预测,而 TD(1) 就是MC方法。
前向 TD($\pmb\lambda$)
前向 TD($\lambda$) 用未来的奖励更新当前状态,但在引入参数 $\lambda$ 后,$G_t^\lambda$ 的计算用到了将来时刻的值函数,因此需要等到整个回合结束后再计算,这和MC方法的要求一样,因此就有了和MC方法一样的劣势。
在实际应用中,前向 TD($\lambda$) 仅仅提供理论解释,而更多使用的是后向 TD($\lambda$)。
后向 TD($\pmb\lambda$)
定义效用追踪 $E_t(s)$ 为
效用追踪的值不需要等到完整的回合结束才能计算出来,它可以每经过一个时刻就得到更新。
后向 TD($\lambda$) 利用TD误差 $\delta_t=R_{t+1}+\gamma v(S_{t+1})-v(S_t)$ 和效用追踪 $E_t(S)$ 来更新值函数,即
- 当 $\lambda=0$ 时,只有当前状态会被更新,即 $E_t(s)=\pmb 1(S_t=s)$,此时就等价于 TD(0) 的更新公式;
-
当 $\lambda=1$ 时,考虑一个回合在时间 $k$ 处访问到状态 $s$,则
$E_t(s)=\gamma E_{t-1}(s)+\pmb 1(S_t=s)=\left\{\begin{array}{ll} 0, & \text{if}~t<k,\\ \gamma^{t-k}, & \text{if}~t\geq k. \end{array}\right.$ 于是
$\displaystyle\sum_{t=1}^{T-1}\alpha\delta_tE_t(s)=\alpha\sum_{t=k}^{T-1}\gamma^{t-k}\delta_t=\alpha(G_k-v(S_k)).$ 所以此时与MC方法的更新公式等价。
事实上,类似地,可以证明前向 TD($\lambda$) 与后向 TD($\lambda$) 对一般的 $\lambda$ 都等价。只需注意到

时序差分控制
On-Policy:Sarsa
与蒙特卡洛控制类似的,把MC方法里面的 $G_t$ 改为TD目标 $R_{t+1}+\gamma v(S_{t+1})$ 即可。具体来说,在Sarsa中,我们学习的是行动值函数,而不是状态值函数,即在一个策略 $\pi$ 下,要估计所有状态以及行动的值 $Q_\pi(s,a)$。
Sarsa的更新公式如下:
与蒙特卡洛控制不同的是,Sarsa在每一个时间步都要更新行动值函数的值,同样的是使用 $\varepsilon$-贪婪探索来改善策略。

用 TD($\lambda$) 替换Sarsa中 TD(0) 来估计行动值函数就可以得到Sarsa($\lambda$)。
首先定义 $n$ 步 $Q$-回报为
在 $n$ 步Sarsa中会朝着 $n$ 步 $Q$-回报来更新:
进一步,对每一步引入参数 $\lambda$ 进行加权,即
从而前向Sarsa($\lambda$)的更新公式即为
而在后向视角下,同样引入效用追踪 $E_t(s,a)$ 为
对于每一个状态动作对 $(s,a)$ 都更新 $q(s,a)$,更新公式如下:
其中 $\delta_t=R_{t+1}+\gamma q(S_{t+1},A_{t+1})-q(S_t,A_t)$。

Off-Policy:Q-learning
Q-Learning是一种Off-Policy的方法。更新公式如下,
这里的 $A’$ 是由目标策略 $\pi(\cdot\mid S_t)$ 产生的后继行动。
具体来说,行为策略 $\mu$ 是对当前行动值函数 $q(s,a)$ 的一个 $\varepsilon$-贪婪策略,而目标策略 $\pi$ 是对当前行动值函数纯贪婪策略:
进一步Q-Learning的TD目标可以化简为
化简后的更新公式如下:
在上面公式中,直接取最大值 $\max\limits_{a’\in\mathcal A}q(S_{t+1},a’)$ 进行学习,因此学习的行动值函数就可以直接近似到最优值,从而不需要进行重要性采样。

Sarsa与Q-Learning的对比
一般情况下,Q-Learning会选择optimal路径,而Sarsa更倾向于safe路径,不过Q-Learning的学习速度比Sarsa快。
- Q-Learning直接学习的是最优策略,而Sarsa在学习最优策略的同时还在做探索。
- Q-Learning直接学习最优策略但最优策略会依赖于训练中产生的一系列数据,所以受样本数据的影响较大,即受训练数据方差的影响较大,甚至会影响函数的收敛。
- Sarsa在学习过程中鼓励探索,学习过程比较平滑,不至于过于激进,导致出现像Q-Learning可能遇到一些特殊的最优“陷阱”。
在实际应用中,如果是在模拟环境中训练强化学习模型,推荐使用Q-Learning;如果是在线生产环境中训练模型,则推荐使用Sarsa。
动态规划与时序差分的对比与关系
下图对比了二者的贝尔曼方程。
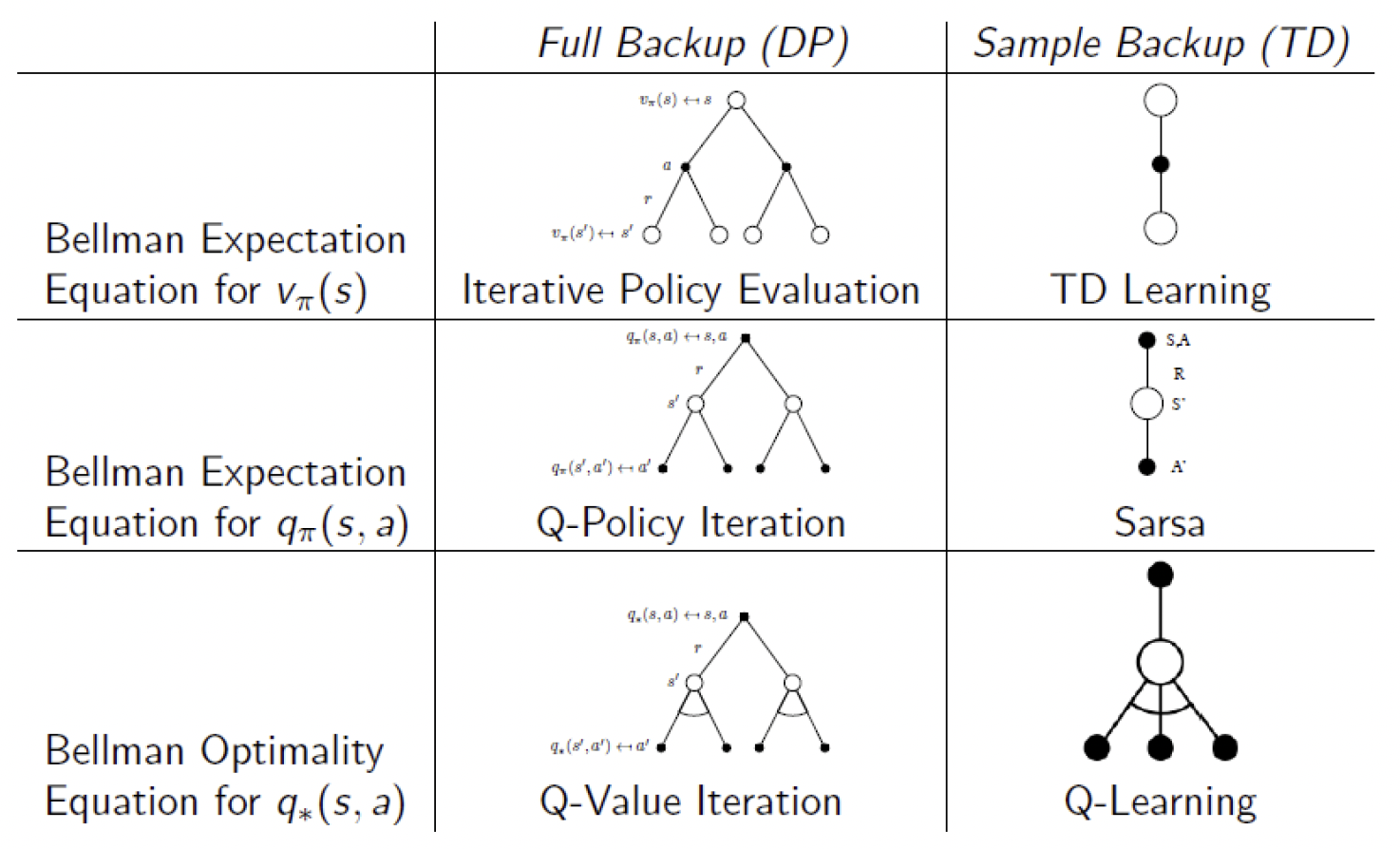
下图对比了二者的更新公式。

一些拓展
Expected Sarsa
在Expected Sarsa中不是用样本的状态值函数,而是使用其期望:
Expected Sarsa性能比Sarsa好,但是花销更大。

Double Q-Learning
在Q-Learning中使用了最大化函数,会引起估计的值函数比真实值要大(称为最大化偏差)的问题。为了避免这个问题的出现,我们将经验分成两个部分,用来学习两个估计。在对行动值函数做估计时,用其中一个决定最优的行动,另一个决定这个最优行动的值的估计。这就是Double Q-Learning。它的更新公式如下:
分别独立地学习两个估计:
注意,Double Q-Learning用了双倍的内存,但是计算次数并没有改变。

后记
本文内容来自中国科学技术大学《强化学习》(2022Fall)课件。
如对本文内容有任何疑问,请联系 watthu@mail.ustc.edu.cn。