标准的蒙特卡洛方法或者蒙特卡洛重要性抽样方法的一个严重缺点是,在实施中后验分布的形式必须完全已知。因此其他一些替代算法来产生近似的蒙特卡洛样本,最流行的就是蒙特卡洛马尔可夫链算法(MCMC),它通过从一个平稳分布是目标分布的马尔可夫链中抽样。
MCMC中的马尔可夫链
定义(马尔可夫链) 一列随机变量 ${X_n,n\geq0}$ 称为马尔可夫链,如果对任何的 $n$,给定当前值 $X_n$,过去值 ${X_k,k\leq n-1}$ 与将来值 ${X_k,k\geq n+1}$ 相互独立。
从定义中可以看出,对任何一列状态 $i_0,i_1,\dots,i_{n-1},i,j$ 及任何 $n\geq0$,有
所谓时间齐次的马尔可夫链,是指在给定 $X_n=x$ 以及过去值 $X_j(j\leq n-1)$ 时 $X_{n+1}$ 的条件分布仅仅依赖于 $x$,与过去值 $X_j(j\leq n-1)$ 和 $n$ 无关。
- 如果 $X_n$ 的状态空间 $\mathcal S$ 可数,则时间齐次等价于指定转移概率矩阵 $\pmb P=(p_{ij})$,使得 $p_{ij}=\mathbb P(X_{n+1}=j\mid X_n=i)$,$\forall i,j\in\mathcal S$。
- 如果 $X_n$ 的状态空间 $\mathcal S$ 不可数,则时间齐次等价于指定一个转移核 $P(x,A)$,使得 $P(x,A)=\mathbb P(X_{n+1}\in A\mid X_n=x)$ 表示从任意 $x\in\mathcal S$ 一步转移到可测集 $A\subset\mathcal S$ 的概率。
对时间齐次的马尔可夫链,记 $\pi_n$ 为 $n$ 时刻马尔可夫链处于各状态的分布向量,则有
其中 $\pi_0$ 为马尔可夫链的初始分布。在MCMC中,我们仅关注时间齐次的马尔可夫链。
定义(平稳分布) 一个概率分布 $\pi={\pi_i,i\geq0}$ 对一个转移概率矩阵 $\pmb P$ 或者其对应的马尔可夫链 ${X_n}$ 而言,称为平稳的或者不变的,如果初始值 $X_0$ 的分布为 $\pi$,则对任意 $n\geq1$,$X_n$ 的分布也为 $\pi$。
- 在状态空间可数的情况下,上述定义可以转化成向量形式:$\pi=\pmb P\pi$。
- 在状态空间不可数的情况下,上述定义等价于 $\displaystyle\pi(A)=\int_{\mathcal S}P(x,A)\pi(x)\text{d}x,\forall A\subset\mathcal S$。
定理(细致平稳条件) 设 $\pi$ 为一个取值于可数状态空间 $\cal S$ 上的一个概率分布,如果一个马尔可夫链的转移概率满足对 $n=0,1,\dots$ 有
则 $\pi$ 为该马尔可夫链的平稳分布,称上式为细致平稳方程。
我们知道,如果马尔可夫链是不可约、遍历(非周期、正常返)的,则 $\pi$ 是其唯一的平稳分布。
-
不可约:对任意两个状态 $i,j\in\cal S$,从状态 $i$ 出发以正概率转移到状态 $j$,即对某个 $n\geq1$ 有
$p_{ij}^{(n)}=\mathbb P(X_n=j\mid X_0=i)>0.$ 具有不可约性的马尔可夫链意味着从任意状态出发总可到达任一其它状态。
-
非周期:返回任一状态的次数的最大公约数是1,即
$\text{gcd}\{n:\mathbb P(X_n=i\mid X_0=i)>0\}=1.$ 非周期的马尔可夫链可以保证其不会陷入循环当中。
-
正常返:返回常返状态的平均返回时间有限,即
$\mu_i=\mathbb E(T_i)<\infty,$ 其中 $T_i=\inf{n\geq1:X_n=i\mid X_0=i}$ 为首次返回状态 $i$ 的时刻。
正常返的马尔可夫链可以保证转移概率的极限不是0。
定理(马尔可夫链的极限定理) 设 ${X_n,n\geq0}$ 为一具有可数状态空间 $\cal S$ 的马尔可夫链,其转移概率矩阵为 $\pmb P$。进一步假设它是不可约、非周期的,有平稳分布 $\pi={\pi_i:i\in\cal S}$,则有
对 $X_0$ 的任意初始分布 $\pi$。
这一定理告诉我们,对比较大的 $n$,$X_n$ 的分布会接近 $\pi$。
定理(马尔可夫链的大数定律) 假设 ${X_n,n\geq0}$ 为一具有可数状态空间 $\cal S$ 的马尔可夫链,其转移概率矩阵为 $\pmb P$。进一步假设它是不可约的,有平稳分布 $\pi={\pi_i:i\in\cal S}$,则对任何有界函数 $h:\mathcal S\rightarrow\mathbb R$ 以及初始值 $X_0$ 的任意初始分布有
当状态空间不可数,马尔可夫链 ${X_n,n\geq0}$ 不可约且有平稳分布 $\pi$ 时,也有
上述定理给出了一个十分有用的结论:给定集合 $\cal S$ 上的概率分布 $\pi$,以及 $\cal S$ 上的实函数 $h(\theta)$,要计算积分
当从后验分布 $\pi(\theta\mid\pmb x)$ 中难以抽样时,则可以构造一个马尔可夫链,使得其状态空间为 $\cal S$ 且其平稳分布 $\pi$ 就是目标后验分布 $\pi(\cdot\mid\pmb x)$,从一初始值 $\theta_0$ 出发,将此链运行一段时间,生成样本 $\theta_0,\theta_1,\dots,\theta_{n-1}$,由大数定律可知
是所要求积分 $\mu$ 的一个相合估计。这就是所谓的马尔可夫链蒙特卡洛(MCMC)方法。
MCMC的相关术语
从前面的表述中我们可以看到,当从后验分布 $\pi(\theta\mid\pmb x)$ 中难以直接抽样时,我们需要
- 构造一个不可约、非周期的马尔可夫链使其平稳分布就是目标后验分布 $\pi(\cdot\mid\pmb x)$;
- 从该马尔可夫链中产生足够长时间的状态,使其达到平稳状态;
- 利用平稳状态下的样本,计算后验分布的样本数字特征,获得相应的蒙特卡洛积分的模拟结果。
实施过程中的相关术语介绍如下。
- 初始值(initial value):初始值用来初始化一个马尔可夫链。
- 如果初始值远离后验密度的最高区域,且算法的迭代次数大小不足以消除初始值的影响,则它对后验推断可能会造成影响。
- 合理的初始值可以是靠近后验分布的中心位置或似然函数的最大值点,不过靠近似然函数的最大值点在一些场合下已经被证明不是一个很好的选择。
- 如果先验分布是有信息的,也可以选择先验分布的期望或众数作为初始值。
- 一般地,可以考虑去掉开始一段时间的迭代值,或者从不同的初始值出发获得抽样(最推荐的做法)等。
- 预烧期(burnin period):用以保证链达到平稳状态所运行的时间。
- 为了避免初始值的影响,预烧期中迭代值将被从样本中去除。
- 只要链运行的时间足够长,去除预烧期对后验推断几乎没有影响。
- 筛选间隔(thinning interval)或抽样步长(sampling lag)
- 由于马尔可夫链产生的样本并不是相互独立的,因此如果需要独立样本,就需要监视样本产生的自相关图,选择抽样步长 $L>1$ 使得 $L$ 步长以后的自相关性很低。
- 于是通过每次间隔 $L$ 个样本抽取一个来获得(近似)独立的样本。
- 迭代保持数(iteration hold number)
- 设迭代总次数为 $J$,预烧期迭代数为 $B$,则提供给后验贝叶斯分析用的实际样本数 $T=J-B$;而如果考虑一个抽样步长 $L$,则最终的(近似)独立样本数为 $T’=(J-B)/L$。
- 蒙特卡洛误差(MC error):度量了每一个估计因为随机模拟而导致的波动性。
下面我们单独拎出蒙特卡洛误差来详细展开。
由于在一定正则条件下
其中 $\sigma_h^2=\text{Var}^\pi[h(\theta_1)]+2\sum\limits_{i=2}^{\infty}\text{Cov}^\pi[h(\theta_1),h(\theta_i)]$。因此,我们使用 $\sigma_h$ 来度量估计量 $\overline{\mu}_T$ 中的MC误差,其估计精度应该随着样本量递增,因而MC误差必然很低。
在实际问题中,估计 $\sigma_h$ 的方法有:组平均(batch mean)方法和窗口估计量(window estimator)方法。
-
(非重叠)组平均方法
首先将生成的 $T$ 个样本分成 $K$ 个组,每个组 $\nu=T/K$ 个。一般 $\nu$ 和 $K$(常取30或50)都要比较大,以使得方差的估计量是相合的,也可以减少自相关性。然后计算组内均值
$\displaystyle\overline{h(X)}_b=\dfrac{1}{\nu}\sum_{t=(b-1)\nu+1}^{b\nu}h(\theta_{(t)}),\quad b=1,\dots,K$ 和总的样本均值 $\displaystyle\overline{h(X)}=\dfrac{1}{K}\sum_{b=1}^K\overline{h(X)}_b$,则均值的MC误差估计为
$\displaystyle\text{MCE}(\overline{\mu}_T)=\hat{\text{SE}}(\overline{h(X)})=\sqrt{\dfrac{1}{K(K-1)}\sum_{b=1}^K[\overline{h(X)}_b-\overline{h(X)}]^2}.$ -
窗口估计量方法
这种方法基于Roberts(1996)对自相关样本的样本方差表示
$\displaystyle\text{MCE}(\overline{\mu}_T)=\dfrac{\hat{\sigma}}{\sqrt{T}}\sqrt{1+2\sum_{k=1}^{\infty}\hat{\rho}_k(h(\theta))},$ 其中 $\hat{\sigma}$ 是 $h(\theta_1)$ 的后验标准差的估计,$\hat{\rho_k}(h(\theta))$ 是估计 $h(\theta_{(t)})$ 与 $h(\theta_{(t+k)})$ 的 $k$ 阶自相关系数。
显然,对很大的 $k$,自相关系数 $\hat{\rho}_k$ 由于样本量很少而不能很好的估计,且对充分大的 $k$,自相关将接近0。因此,取一个窗口 $w$,使得其后的自相关系数都很小,在计算时就可以忽略。这种基于窗口的MC误差为
$\displaystyle\text{MCE}(\overline{\mu}_T)=\dfrac{\hat{\sigma}}{\sqrt{T}}\sqrt{1+2\sum_{k=1}^{w}\hat{\rho}_k(h(\theta))},$ 其中 $\displaystyle\hat{\sigma}=\dfrac{1}{T-1}\sum_{t=1}^T(h(\theta_{(t)})-\overline{\mu}_T)^2$。
MCMC算法收敛性
所谓算法收敛性,是指所得到的链是否达到了平稳状态。如果达到了平稳状态,则我们得到的样本可以认为是从目标分布中抽取的样本。一般来说,我们并不知道算法需要运行多长时间才能达到平稳状态,因此监视链的收敛性是MCMC计算方法中的本质问题。
- 监视蒙特卡洛误差:较小的MC误差表明在计算感兴趣的量时精度较高,即MC误差越小表明马尔可夫链的收敛性越好。
- 样本路径图:将马尔可夫链生成的值对迭代次数作图,如果所有的值都在一个区域里没有明显的周期性或趋势性,则认为收敛性已经达到。
- 累积均值图:将马尔可夫链的累积均值对迭代次数作图,如果累积均值在经过一些迭代后基本稳定,则认为收敛性已经达到。
- 自相关函数(ACF)图:将马尔可夫链生成样本的自相关函数对迭代次数作图,较低或较高的自相关性分别表明了收敛性的好与坏。
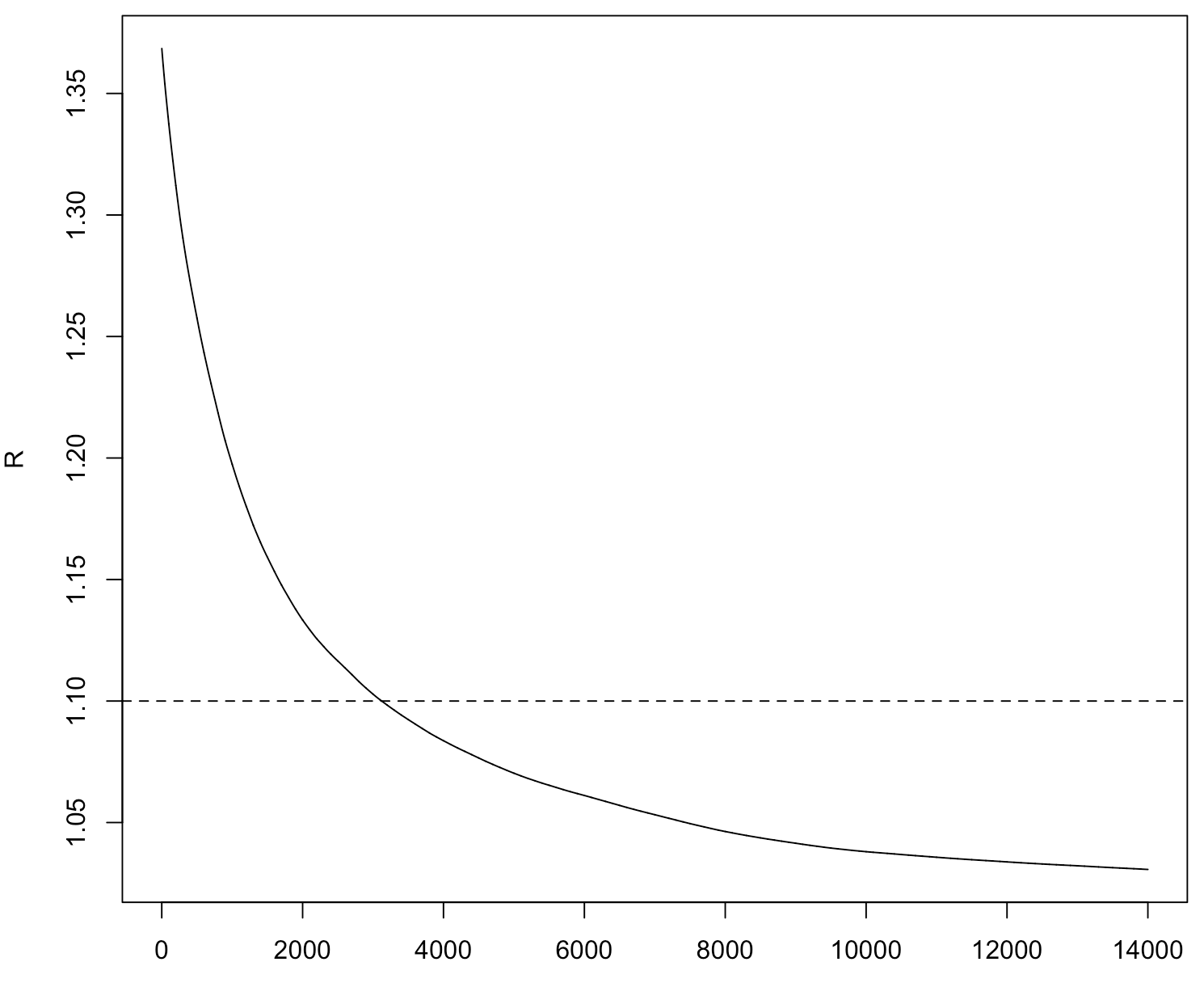
- Gelman-Rubin方法:对多个平行链,监视潜在尺度缩减因子 $\sqrt{\hat{R}}$ 是否收敛到1。
上述方法通常为了避免链陷入目标分布的某个局部区域,往往作几个平行的链,它们的初始值非常分散,再看后续的各种图。
下面具体通过对Gelman-Rubin方法的阐述和例子来深入理解这一方法,同时我们也考虑了其他几个监视收敛性的方法。
假设有 $k$ 个链,每个链有 $n$ 个样本,感兴趣的量记为 $\psi$,其在目标分布下有期望 $\mu$ 和方差 $\sigma^2$。记 $\psi_{jt}$ 表示到链 $j$ 的第 $t$ 个样本时 $\psi$ 的值,那么在混合样本中,$\mu$ 的一个无偏估计为 $\hat{\mu}=\overline{\psi}_{\cdot\cdot}$,而链之间的方差 $B/n$ 和链内的方差 $W$ 分别为
从而可以使用 $B$ 和 $W$ 的加权估计 $\sigma^2$:
如果初始值是从目标分布中抽取的,那么 $\hat{V}$ 是 $\sigma^2$ 的无偏估计,但如果初始值过度分散,则会高估 $\sigma^2$。一个自然的想法就是令 $R=\hat{V}/\sigma^2$,则称 $\sqrt{R}$ 为尺度缩减因子,它的估计为
称 $\sqrt{\hat{R}}$ 为潜在尺度缩减因子。当链达到收敛并且产生的数据很大时,$\hat{R}$ 应该趋于1。
例如,目标分布为 $N(0,1)$,提议分布为 $N(X_t,\sigma^2)$,$\psi_{jt}$ 表示第 $j$ 个链前 $t$ 个样本的平均。
# 计算潜在尺度缩减因子
Gelman.Rubin <- function(psi) {
psi <- as.matrix(psi)
k <- nrow(psi); n <- ncol(psi)
psi.means <- rowMeans(psi)
B <- n * var(psi.means)
psi.w <- apply(psi, 1, var)
W <- mean(psi.w)
v.hat <- W * (n - 1) / n + B / n
r.hat <- v.hat / W
return(r.hat)
}
# 采用M-H算法(后续介绍)生成链
normal.chain <- function(sigma, N, X1) {
x <- rep(0, N)
x[1] <- X1
u <- runif(N)
for (i in 2:N) {
xt <- x[i - 1]
y <- rnorm(1, xt, sigma)
r1 <- dnorm(y, 0, 1) * dnorm(xt, y, sigma)
r2 <- dnorm(xt, 0, 1) * dnorm(y, xt, sigma)
if (u[i] <= r1 / r2) { x[i] <- y} else { x[i] <- xt }
}
return(x)
}
sigma <- 1
k <- 4 # numebr of chains
n <- 15000 # length of chains
b <- 1000 # burnin period
x0 <- c(-10, -5, 5, 10) # initial value
X <- matrix(nrow = k, ncol = n)
for (i in 1:k) {
X[i, ] <- normal.chain(sigma, n, x0[i])
}
# 绘制样本路径图
plot(1:n, X[1,], type = "l")
lines(1:n, X[2,], type = "l", col = 2)
lines(1:n, X[3,], type = "l", col = 3)
lines(1:n, X[4,], type = "l", col = 4)
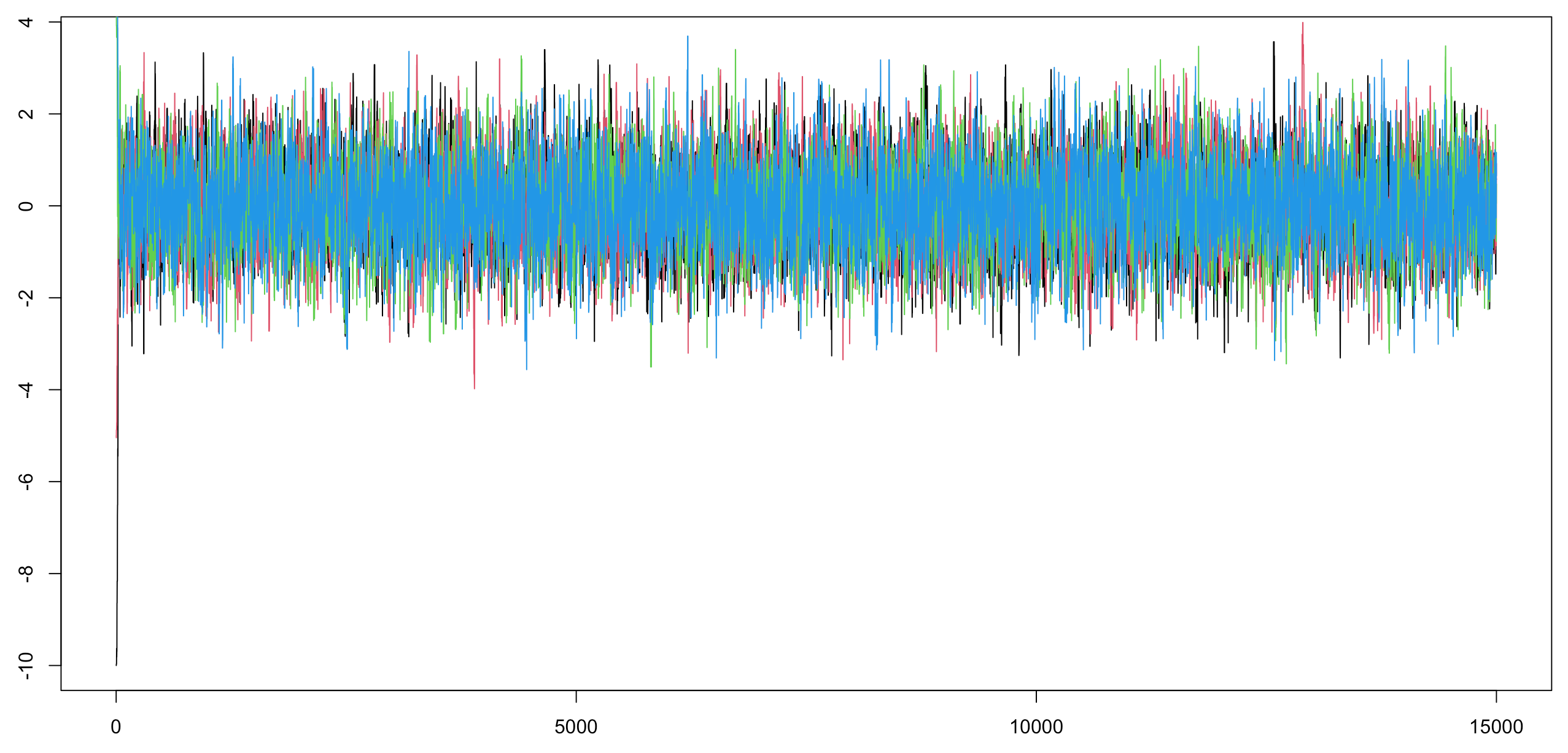
# 绘制累积均值图
psi <- t(apply(X, 1, cumsum))
for (i in 1:k) {
psi[i,] <- psi[i,] / (1:n)
}
par(mfrow = c(2,2))
for (i in 1:k) {
plot(psi[i, (b+1):n], type = "l", xlab = i, ylab = bquote(psi))
}
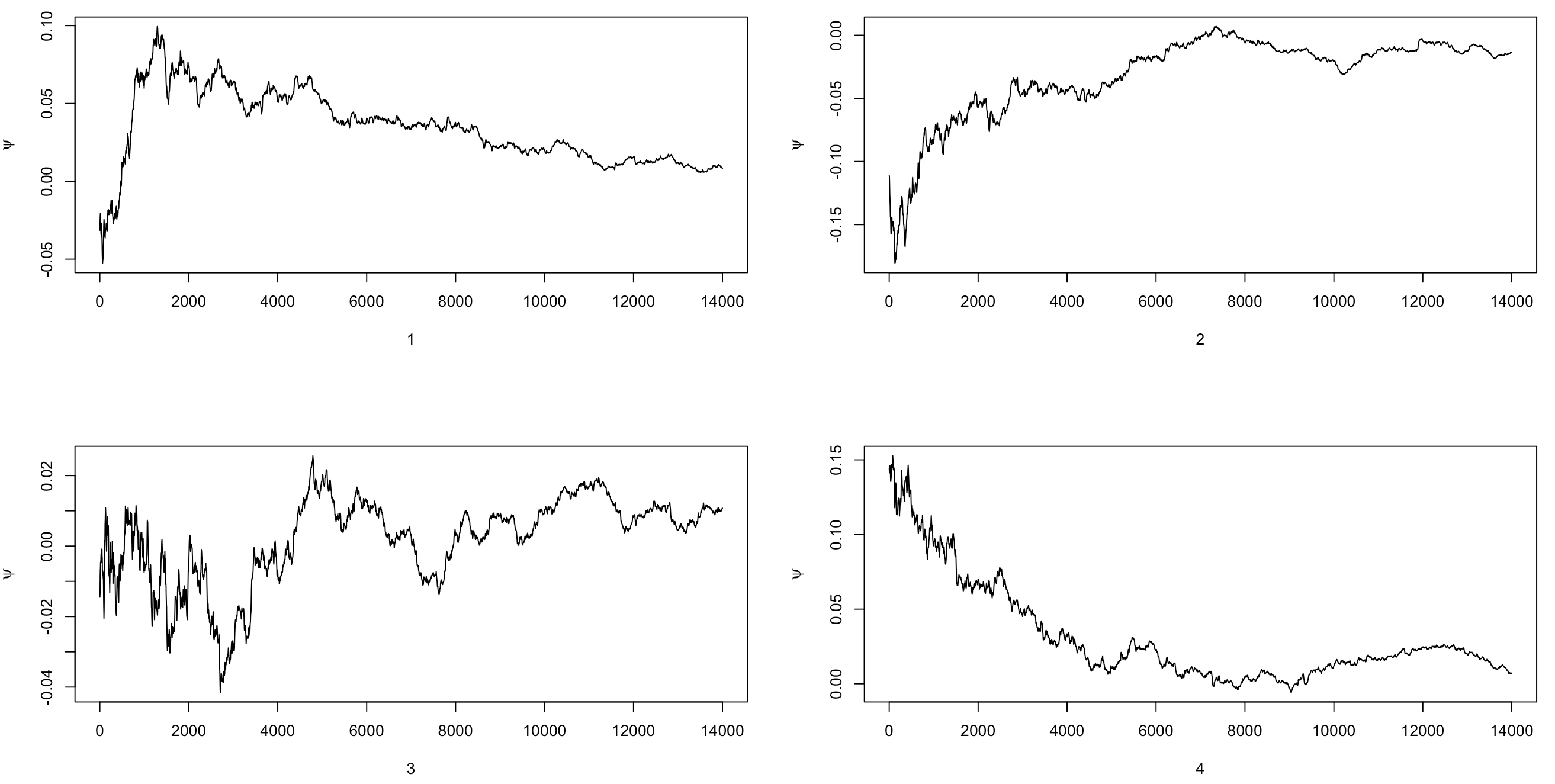
# 绘制潜在尺度缩减因子图
rhat <- rep(0, n)
for (j in (b+1):n) {
rhat[j] <- Gelman.Rubin(psi[, 1:j])
}
plot(rhat[(b+1):n], type = "l", xlab = "", ylab = "R")
abline(h = 1.1, lty = 2)
MCMC抽样方法
MCMC抽样方法的核心问题是确定满足要求(不可约、非周期、正常返且平稳分布为目标抽样分布)的一个马尔可夫链,因此确定从当前值转移到下一个值的规则十分重要。
Metropolis-Hastings算法
假设我们希望从目标分布 $f(x)$ 中抽样,通过M-H算法从初始值 $x_0$ 出发,指定一个从当前值 $x_t$ 转移到下一个值 $x_{t+1}$ 的规则,从而产生马尔可夫链 ${x_0,x_1,\dots,x_n,\dots}$。
具体来说,在给定当前值 $x_t$ 的情况下,
- 从提议分布 $g(\cdot\mid x_t)$ 产生一个候选点 $x’$;
- 计算接受概率
$\alpha(x_t,x')=\min\left\{1,\dfrac{f(x')g(x_t\mid x')}{f(x_t)g(x'\mid x_t)}\right\};$ - 依概率 $\alpha(x_t,x’)$ 接受 $x_{t+1}=x’$,否则 $x_{t+1}=x_t$。
上述过程是有理论保证的。事实上,记 $q_{ij}=g(x_{t+1}=j\mid x_t=i)$,首先由M-H抽样方法产生的序列 ${x_0,x_1,\dots}$ 为一马尔可夫链,其转移概率为
其中 $r(i)=\sum_jq_{ij}\alpha(i,j)$,$\alpha_{i,j}=\min{1,f_jq_{ji}/f_iq_{ij}}$,$\delta_i(j)=1$ 当且仅当 $i=j$。所以
而 $i=j$ 时,$f_i\delta_i(j)(1-r(i))=f_j\delta_j(i)(1-r(j))$,因此细致平稳方程满足,$f$ 即该链的平稳分布。进一步可以验证该链是不可约、正常返、非周期的。此外,如果状态空间是连续的,证明类似,只需将转移概率修改为转移核即可。
注意,提议分布 $g$ 的选择要使得产生的马尔可夫链满足不可约、正常返、非周期且具有平稳分布 $f$ 等正则化条件外,还应满足:
- 提议分布的支撑集包含目标分布的支撑集;
- 容易从提议分布中抽样,常取为已知的分布,如正态分布或 $t$ 分布等;
- 提议分布应使接受概率容易计算;
- 提议分布的尾部要比目标分布的尾部厚。
此外,Robert和Casella(1999)指出,接受概率并非越大越好,因为这可能导致较慢的收敛性;Gelman等(1996)建议当参数维数为1时,接受概率应略小于0.5,当参数维数大于5时,接受概率应降至0.25左右。
例如,使用M-H抽样方法从瑞利(Rayleigh)分布中抽样,其密度函数为
取提议分布为 $\Gamma(X_t,1)$,则使用M-H抽样方法如下:
- 令 $g(\cdot\mid X)$ 为 $\Gamma(X,1)$;
- 从 $\Gamma(1,1)$ 中产生 $X_0$,并存在 $x[1]$ 中;
- 对 $i=2,\dots,N$,重复:
- 从 $\Gamma(X_t,1)=\Gamma(x[i-1],1)$ 中产生 $Y$;
- 产生 $U\sim U(0,1)$;
-
由 $X_t=x[i-1]$,计算
$r(X_t,Y)=\dfrac{f(Y)g(X_t\mid Y)}{f(X_t)g(Y\mid X_t)},$ 其中 $f$ 为瑞利密度,$g(Y\mid X_t)$ 为 $\Gamma(X_t,1)$ 的密度在 $Y$ 处的值,$g(X_t\mid Y)$ 为 $\Gamma(Y,1)$ 的密度在 $X_t$ 处的值。
- 若 $U\leq r(X_t,Y)$,则接受 $Y$,令 $X_{t+1}=Y$;否则令 $X_{t+1}=X_t$。将 $X_{t+1}$ 存在 $x[i]$ 里。
- 增加 $t$,返回到循环内的第一步。
f <- function(x, sigma) {
if (any(x < 0)) return(0)
return(x / sigma^2 * exp(-x^2 / (2 * sigma^2)))
}
m <- 10000
sigma <- 4
x <- numeric(m)
x[1] <- rgamma(1, 1, 1)
k <- 0
u <- runif(m)
for (i in 2:m) {
xt <- x[i - 1]
y <- rgamma(1, xt, 1)
r <- f(y, sigma) * dgamma(xt, y, 1) / f(xt, sigma) / dgamma(y, xt, 1)
if (u[i] <= r) { x[i] <- y }
else { x[i] <- xt; k <- k + 1 }
}
代码得到k的值约为3000,可见约有30%的点被拒绝了,接受的概率较高,算法效率较高。
b <- 2000 # burnin period
y <- x[(b+1):m]
a <- ppoints(100)
QR <- sigma * sqrt(-2 * log(1 - a))
Q <- quantile(x, a)
par(mfrow = c(1,2))
hist(y, breaks = "scott", xlab = "sample", freq = FALSE)
lines(QR, f(QR, 4))
qqplot(QR, Q, xlab = "Rayleigh Quantiles", ylab = "Sample Quantiles")

根据提议分布 $g$ 的不同选择,M-H抽样方法衍生出了几个不同的变种。
-
Metropolis抽样方法
在Metropolis抽样方法中,提议分布是对称的,即 $g(\cdot\mid X_n)$ 满足 $g(X\mid Y)=g(Y\mid X)$,因此接受概率为
$\alpha(X_t,Y)=\min\left\{1,\dfrac{f(Y)}{f(X_t)}\right\}.$ -
随机游动Metropolis抽样方法
随机游动Metropolis抽样方法是Metropolis方法的一个应用例子。假设候选点 $Y$ 从一个对称的提议分布 $g(Y\mid X_t)=g(\vert X_t-Y\vert)$ 中产生,则在每一次迭代中,从 $g(\cdot)$ 中产生一个随机增量 $Z$,然后 $Y=X_t+Z$。比如增量 $Z$ 可以从正态分布中产生,此时 $Y\mid X_t\sim N(X_t,\sigma^2)$,$\sigma^2>0$。
例如,考虑如下贝叶斯推断(投资模型)问题。假设有五种股票被跟踪记录了250个交易日每天的表现,在每一个交易日,收益最大的股票被标记出来。用 $X_i$ 表示股票 $i$ 在250个交易日中胜出的天数,则记录得到的频数 $(x_1,\dots,x_5)$ 为随机变量 $(X_1,\dots,X_5)$ 的观测值。基于历史数据,假设这五种股票在任何给定的一个交易日能胜出的先验机会比率为 $1:(1-\beta):(1-2\beta):2\beta:\beta$,这里 $\beta\in(0,0.5)$ 是一个未知的参数。设 $\beta$ 的先验分布为区间 $(0,0.5)$ 上的均匀分布,在有了当前这250个交易日的数据后,使用贝叶斯方法对此比例进行更新。
解: 根据所述模型,$\pmb X=(X_1,\dots,X_5)$ 在给定 $\beta$ 的条件下服从多项分布 $M(5,\pmb p)$,概率向量为
令 $\beta$ 的先验分布 $\pi(\beta)$ 为 $(0,0.5)$ 上的均匀分布,$\pmb b$ 的似然函数为 $l(\pmb p\mid\pmb x)$,因此后验分布
显然不能直接从后验分布中产生随机数,考虑使用随机游动Metropolis抽样方法产生一个马尔可夫链,使其平稳分布为此后验分布,提议分布为对称的均匀分布,然后从此链中产生目标分布的随机数来估计 $\beta$。此时,接受概率为
其中 $f(\cdot)=\pi(\cdot\mid\pmb x)$ 为目标分布。
beta <- 0.2
m <- 5000
days <- 250
x <- numeric(m)
i <- sample(1:5, size = days, replace = TRUE,
prob = c(1, 1-beta, 1-2*beta, 2*beta, beta))
win <- tabulate(i)
代码输出93 64 46 30 17,这就是 $\pmb X=(X_1,\dots,X_5)$ 的观测值 $\pmb x=(x_1,\dots,x_5)$。
prob <- function(y, win) {
if (y < 0 || y >= 0.5) { return(0) }
return(1^win[1] * (1-y)^win[2] * (1-2*y)^win[3] * (2*y)^win[4] * y^win[5] / 3^sum(win))
}
u <- runif(m)
v <- runif(m, -0.25, 0.25)
x[1] <- 0.25
for (i in 2:m) {
y <- x[i - 1] + v[i]
if (u[i] <= prob(y, win) / prob(x[i - 1], win)) { x[i] <- y }
else { x[i] <- x[i - 1] }
}
par(mfrow = c(1, 2))
plot(x, type = "l")
abline(h = beta, v = 501, lty = 3)
xb <- x[-(1:500)]
hist(xb, prob = TRUE, xlab = bquote(beta), ylab = "X", main ="")
z <- seq(min(xb), max(xb), length = 100)
lines(z, dnorm(z, mean(xb), sd(xb)))
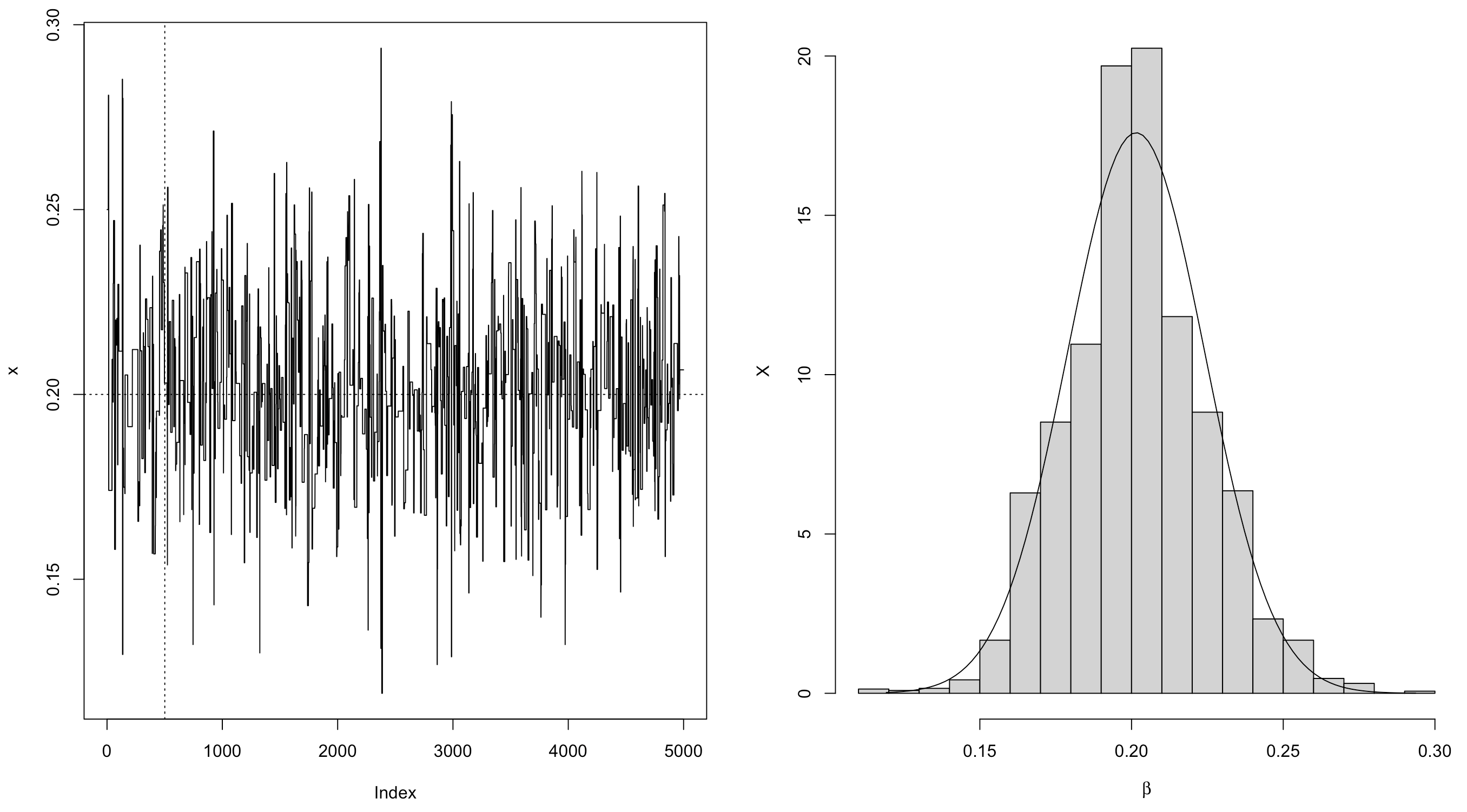
可以看到 $\beta$ 的后验期望接近0.2(真值)。
-
独立抽样方法
独立抽样是M-H抽样方法的另一个特殊情形,其中的提议分布不依赖于链的前一步状态值,因此 $g(Y\mid X_t)=g(Y)$,此时接受概率为
$\alpha(X_t,Y)=\min\left\{1,\dfrac{f(Y)g(X_t)}{f(X_t)g(Y)}\right\}.$
例如,假设从一个正态混合分布 $pN(\mu_1,\sigma_1^2)+(1-p)N(\mu_2,\sigma_2^2)$ 中观测到一个样本 $\pmb z=(z_1,\dots,z_n)$,利用独立抽样方法求 $p$ 的估计。
解: 在 $p$ 无先验信息可以利用时,考虑先验分布 $\pi(p)$ 为 $U(0,1)$,则 $p$ 的后验分布为
其中 $f_1,f_2$ 分别为两个正态的密度。考虑提议分布为贝塔分布 $Be(a,b)$,其密度函数为 $g(y)\propto y^{a-1}(1-y)^{b-1}$,接受概率为
下面进行模拟。
m <- 5000
xt <- numeric(m)
a <- 1
b <- 1
p <- 0.2
n <- 100
mu <- c(0, 5)
sigma <- c(1, 1)
i <- sample(1:2, size = n, replace = TRUE, prob = c(p, 1-p))
x <- rnorm(n, mu[i], sigma[i])
u <- runif(m)
y <- rbeta(m, a, b)
xt[1] <- 0.5
for (i in 2:m) {
fy <- y[i] * dnorm(x, mu[1], sigma[1]) + (1 - y[i]) * dnorm(x, mu[2], sigma[2])
fx <- xt[i-1] * dnorm(x, mu[1], sigma[1]) + (1 - xt[i-1]) * dnorm(x, mu[2], sigma[2])
r <- prod(fy / fx) * dbeta(xt[i-1], a, b) / dbeta(y[i], a, b)
if (u[i] <= r) { xt[i] <- y[i] }
else { xt[i] <- xt[i-1] }
}
par(mfrow = c(1, 2))
plot(xt, type = "l", ylab = "p")
abline(h = p, v = 101, lty = 3)
hist(xt[-(1:100)], main = "", xlab = "p", prob = TRUE)
z <- seq(min(xt), max(xt), length = 100)
lines(z, dnorm(z, mean(xt), sd(xt)))
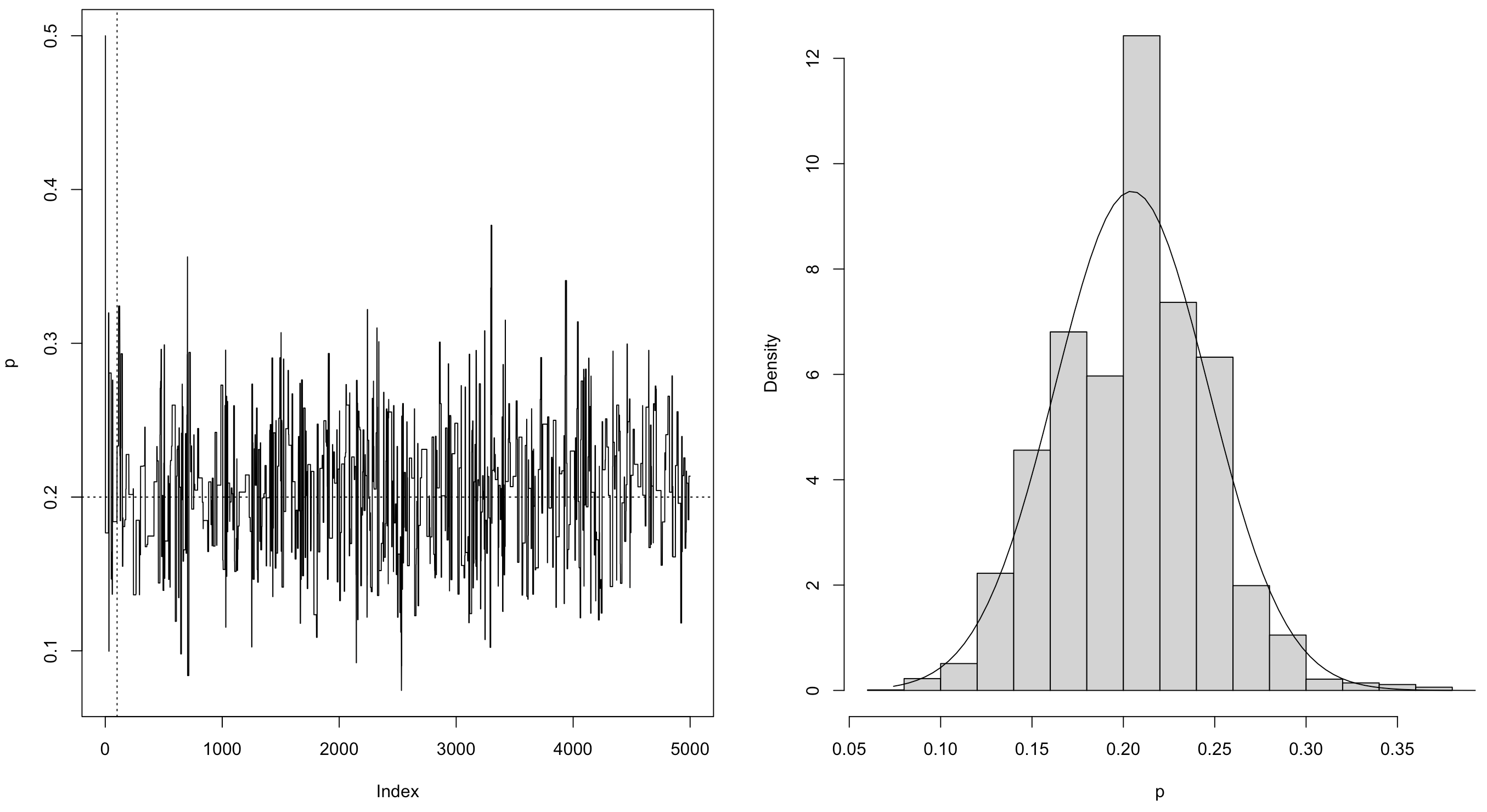
可以看到 $p$ 的后验期望接近0.2(真值)。
-
逐分量的M-H抽样方法
当状态空间为 $k$ 维 $(k>1)$ 时,不整体更新 $\pmb X_t$,而是对其分量逐个进行更新,即称为逐分量的M-H抽样方法。这样做更方便、更有效率。
记 $\pmb X_t=(X_{t,1},\dots,X_{t,k})$ 为第 $t$ 步链的状态,$\pmb X_{t,-i}=(X_{t,1},\dots,X_{t,i-1},X_{t,i+1},\dots,X_{t,k})$ 为第 $t$ 步除第 $i$ 个分量外其他分量的状态;$f(\pmb x)=f(x_1,\dots,x_k)$ 为目标分布,$f(x_i\mid\pmb x_{-i})=f(\pmb x)/\int f(x_1,\dots,x_k)\text{d}x_i$ 表示 $X_i$ 对其它分量的条件密度。用逐分量的M-H抽样方法更新 $\pmb X_t$ 由 $k$ 步构成:
-
对 $i=1,\dots,k$,从第 $i$ 个提议分布 $g_i(y\mid X_{t,i},\pmb X_{t,-i}^\star)$ 中产生 $Y_i$,这里
$\pmb X_{t,-i}^\star=(X_{t+1,1},\dots,X_{t+1,i-1},X_{t,i+1},\dots,X_{t,k}).$ -
然后 $Y_i$ 以概率
$\alpha(\pmb X_{t,-i}^\star,X_{t,i},Y_i)=\min\left\{1,\dfrac{f(Y_i\mid\pmb X_{t,-i}^\star)g_i(X_{t,i}\mid Y_i,\pmb X_{t,-i}^\star)}{f(X_{t,i}\mid\pmb X_{t,-i}^\star)g_i(Y_i\mid X_{t,i},\pmb X_{t,-i}^\star)}\right\}$ 被接受。
-
例如,考虑54位老年人的智力测试成绩(WAIS,0~20分),研究的兴趣在于发现老年痴呆症与WAIS的关系。
解: 采用如下简单的Logistic回归模型
其中 $Y_i=1$ 表示第 $i$ 个人患有老年痴呆症,$x_i$ 表示第 $i$ 个人的WAIS成绩,则似然函数为
考虑 $\beta_0$ 和 $\beta_1$ 的先验分布 $\pi(\beta_0,\beta_1)=\pi_0(\beta_0)\pi_1(\beta_1)$ 为如下的独立正态分布:
因此后验分布为
下面用逐分量随机游动M-H抽样方法从此分布中产生随机数。提议分布取
这里 $\pmb\beta’=(\beta_0’,\beta_1’)^\textsf{T}$,而 $\pmb\beta=(\beta_0,\beta_1)^\textsf{T}$。算法如下:
在 $t=0$ 时,将 $\pmb\beta=(\beta_0,\beta_1)^\textsf{T}$ 赋初始值 $(\beta_0^{(0)},\beta_1^{(0)})^\textsf{T}$,对 $t=1,\dots,T$,重复下列步骤:
- 令 $\pmb\beta=(\beta_0^{(t-1)},\beta_1^{(t-1)})^\textsf{T}$。
- 从提议分布 $N(\beta_0,\overline{s}_{\beta_0}^2)$ 产生候选点 $\beta_0’$。
-
令 $\pmb\beta’=(\beta_0’,\beta_1^{(t-1)})^\textsf{T}$,计算接受概率
$\alpha_0(\pmb\beta,\pmb\beta')=\min\left\{1,\dfrac{\pi(\beta_0',\beta_1\mid\pmb y)}{\pi(\beta_0,\beta_1\mid\pmb y)}\right\}=\min\left\{1,\dfrac{f(\pmb y\mid\beta_0',\beta_1)\pi(\beta_0',\beta_1)}{f(\pmb y\mid\beta_0,\beta_1)\pi(\beta_0,\beta_1)}\right\}.$ - 以概率 $\alpha_0(\pmb\beta,\pmb\beta’)$ 接受 $\pmb\beta=\pmb\beta’$,即将 $\pmb\beta$ 的第一个分量更新为 $\beta_0’$,否则保持其值不变。
- 从提议分布 $N(\beta_1,\overline{s}_{\beta_1}^2)$ 产生候选点 $\beta_1’$。
-
令 $\pmb\beta’=(\beta_0^{(t-1)},\beta_1’)^\textsf{T}$,计算接受概率
$\alpha_1(\pmb\beta,\pmb\beta')=\min\left\{1,\dfrac{\pi(\beta_0,\beta_1'\mid\pmb y)}{\pi(\beta_0,\beta_1\mid\pmb y)}\right\}=\min\left\{1,\dfrac{f(\pmb y\mid\beta_0,\beta_1')\pi(\beta_0,\beta_1')}{f(\pmb y\mid\beta_0,\beta_1)\pi(\beta_0,\beta_1)}\right\}.$ - 以概率 $\alpha_1(\pmb\beta,\pmb\beta’)$ 接受 $\pmb\beta=\pmb\beta’$,即将 $\pmb\beta$ 的第二个分量更新为 $\beta_1’$,否则保持其值不变。
- 令 $\pmb\beta^{(t)}=\pmb\beta$。
- 增加 $t$,返回到第一步。
wais <- read.table("wais.txt", header = TRUE)
x <- wais[,1]; y <- wais[,2]
m <- 10000
beta0 <- c(0, 0) # initial value
mu.beta <- c(0, 0); s.beta <- c(100, 100) # prior parameters
prop.s <- c(0.2, 0.2) # sd of proposal normal
beta <- matrix(nrow = m, ncol = 2)
acc.prob <- 0
current.beta <- beta0
for (t in 1:m) {
prop.beta <- rnorm(2, current.beta, prop.s)
cur.eta <- current.beta[1] + current.beta[2] * x
prop.eta <- prop.beta[1] + prop.beta[2] * x
loga <- (sum(y * prop.eta - log(1 + exp(prop.eta)))
- sum(y * cur.eta - log(1 + exp(cur.eta)))
+ sum(dnorm(prop.beta, mu.beta, s.beta, log = TRUE))
- sum(dnorm(current.beta, mu.beta, s.beta, log = TRUE)))
u <- runif(1)
if (log(u) < loga) {
current.beta <- prop.beta
acc.prob <- acc.prob + 1
}
beta[t,] <- current.beta
}
代码得到的acc.prob为2151,即接受概率约为0.2151%。
erg.mean <- function(x) {
n <- length(x)
result <- cumsum(x) / (1:n)
return(result)
}
diagnostic <- function(x, burnin = 2000, step = 30) {
beta <- x
m <- nrow(x)
idx <- seq(1, m, step)
idx2 <- seq(burnin + 1, m)
par(mfrow = c(3, 2))
plot(idx, beta[idx, 1], type = "l", xlab = "Iterations",
ylab = "Values of beta0", main = "(a) Trace Plot of beta0")
plot(idx, beta[idx, 2], type = "l", xlab = "Iterations",
ylab = "Values of beta1", main = "(b) Trace Plot of beta1")
ergbeta0 <- erg.mean(beta[, 1])
ergbeta02 <- erg.mean(beta[idx2, 1])
ylims0 <- range(c(ergbeta0, ergbeta02))
ergbeta1 <- erg.mean(beta[, 2])
ergbeta12 <- erg.mean(beta[idx2, 2])
ylims1 <- range(c(ergbeta1, ergbeta12))
plot(idx, ergbeta0[idx], type = "l", xlab = "Iterations",
ylab = "Values of beta0", main = "(c) Ergodic Mean Plot of beta0", ylim = ylims0)
lines(idx2, ergbeta02[idx2 - burnin], col = 2, lty = 2)
plot(idx, ergbeta1[idx], type = "l", xlab = "Iterations",
ylab = "Values of beta1", main = "(d) Ergodic Mean Plot of beta1", ylim = ylims1)
lines(idx2, ergbeta12[idx2 - burnin], col = 2, lty = 2)
index4 <- seq(burnin + 1, m, step)
acf(beta[index4, 1], main = "(e) Autocorrelations Plot for beta0", sub = "(Thin = 30 iterations)")
acf(beta[index4, 2], main = "(f) Autocorrelations Plot for beta1", sub = "(Thin = 30 iterations)")
}
burnin <- 2000
diagnostic(beta, burnin, step = 30)
apply(beta[(burnin+1):m,], 2, mean)
apply(beta[(burnin+1):m,], 2, sd)
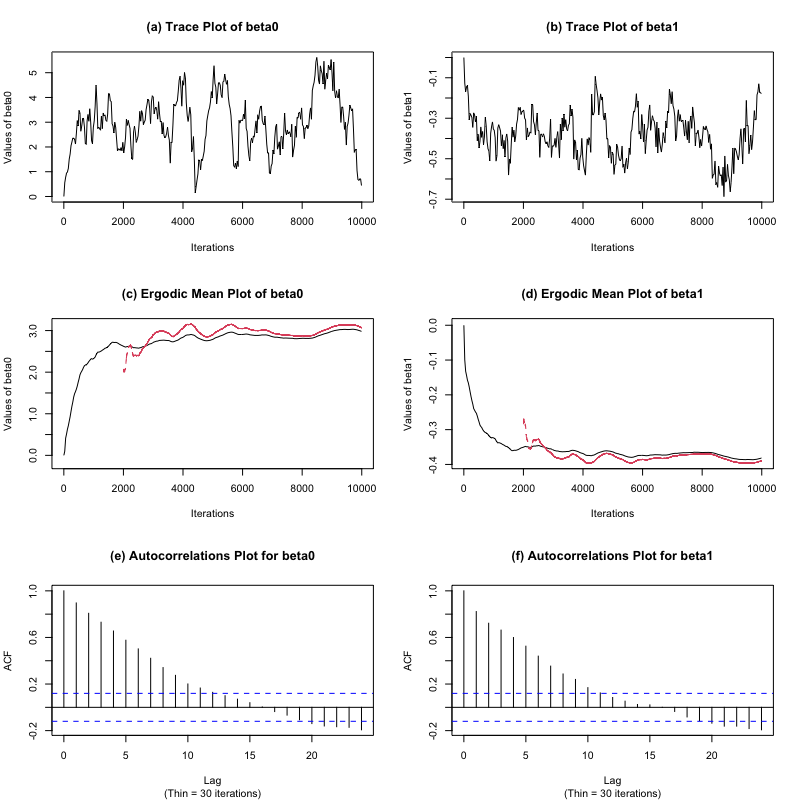
可以看到,遍历均值图去掉前2000次迭代后趋于平稳,链的自相关函数图显示收敛较快。最后,$\beta_0$ 和 $\beta_1$ 的链的样本均值分别是3.0690682 -0.3892655,样本标准差分别是1.1568550 0.1134388。
Gibbs抽样方法
Gibbs抽样方法特别适合于目标分布是多元的场合,其最令人感兴趣的方面是为了产生不可约、非周期、并以高维空间的目标分布作为其平稳分布的马尔可夫链,只需要从一些一元分布(全条件分布)中进行抽样就可以了。即将从多元目标分布中抽样转化为从一元目标分布抽样,这是Gibbs抽样的重要性所在。
令 $\pmb X=(X_1,\dots,X_p)\in\mathbb R^p$ 为随机变量,其联合分布 $f(\pmb x)$ 为目标分布。记 $\pmb X_{-i}=(X_1,\dots,X_{i-1},X_{i+1},\dots,X_p)\in\mathbb R^{p-1}$,并记 $X_i\mid\pmb X_{-i}$ 的满(全)条件密度为 $f(x_i\mid\pmb x_{-i})$ $(i=1,\dots,p)$。Gibbs抽样方法是从这 $p$ 个条件分布中产生候选点,以解决直接从 $f$ 中进行抽样的困难。Gibbs抽样从一个初始值 $\pmb x^{(0)}=(x_1^{(0)},\dots,x_p^{(0)})$ 出发,按下述过程迭代更新分量:
有时候对所有分量完成一次更新比较复杂,可以采用随机化的方式,每次仅更新一个分量(随机选择),而其它分量保持不变。注意,这里无需计算每一个候选点的接受概率 $\alpha$,全部接受。
下面定理保证了Gibbs抽样方法的合理性——正性条件下全条件分布唯一地确定联合分布。
定理(Hammersley-Clifford) 设 $(X_1,\dots,X_p)$ 满足正性条件,即 $X_i$ 的边际密度 $f_i(x_i)>0$ $(i=1,\dots,p)$ 意味着联合密度 $f(x_1,\dots,x_p)>0$,则对所有 $(\xi_1,\dots,\xi_p)\in\text{supp}(f)$ 有
注意此定理并没有保证对任意组全条件分布存在联合分布。例如,设 $X_1\mid X_2\sim Exp(\lambda X_2)$,$X_2\mid X_1\sim Exp(\lambda X_1)$,则由Hammersley-Clifford定理,
而 $\displaystyle\iint\exp(-\lambda x_1x_2)\text{d}x_1\text{d}x_2=+\infty$,即给定全条件密度不存在联合密度。
可以证明在正性条件下,Gibbs抽样方法产生一个不可约、常返的马尔可夫链,$f$ 为该链的平稳分布。
例如,使用Gibbs抽样方法产生二元正态分布 $N(\mu_1,\mu_2,\sigma_1^2,\sigma_2^2,\rho)$ 的随机数。注意到
于是通过如下代码就可以实现目的。
m <- 10000
burnin <- 1000
X <- matrix(0, m, 2)
rho <- 0.8
mu <- c(0, 2)
sigma <- c(1, 0.5)
s <- sqrt(1 - rho^2) * sigma
X[1,] <- mu
for (i in 2:m) {
x2 <- X[i-1, 2]
m1 <- mu[1] + rho * (x2 - mu[2]) * sigma[1] / sigma[2]
X[i,1] <- rnorm(1, m1, s[1])
x1 <- X[i, 1]
m2 <- mu[2] + rho * (x1 - mu[1]) * sigma[2] / sigma[1]
X[i,2] <- rnorm(1, m2, s[2])
}
x <- X[-(1:burnin),]
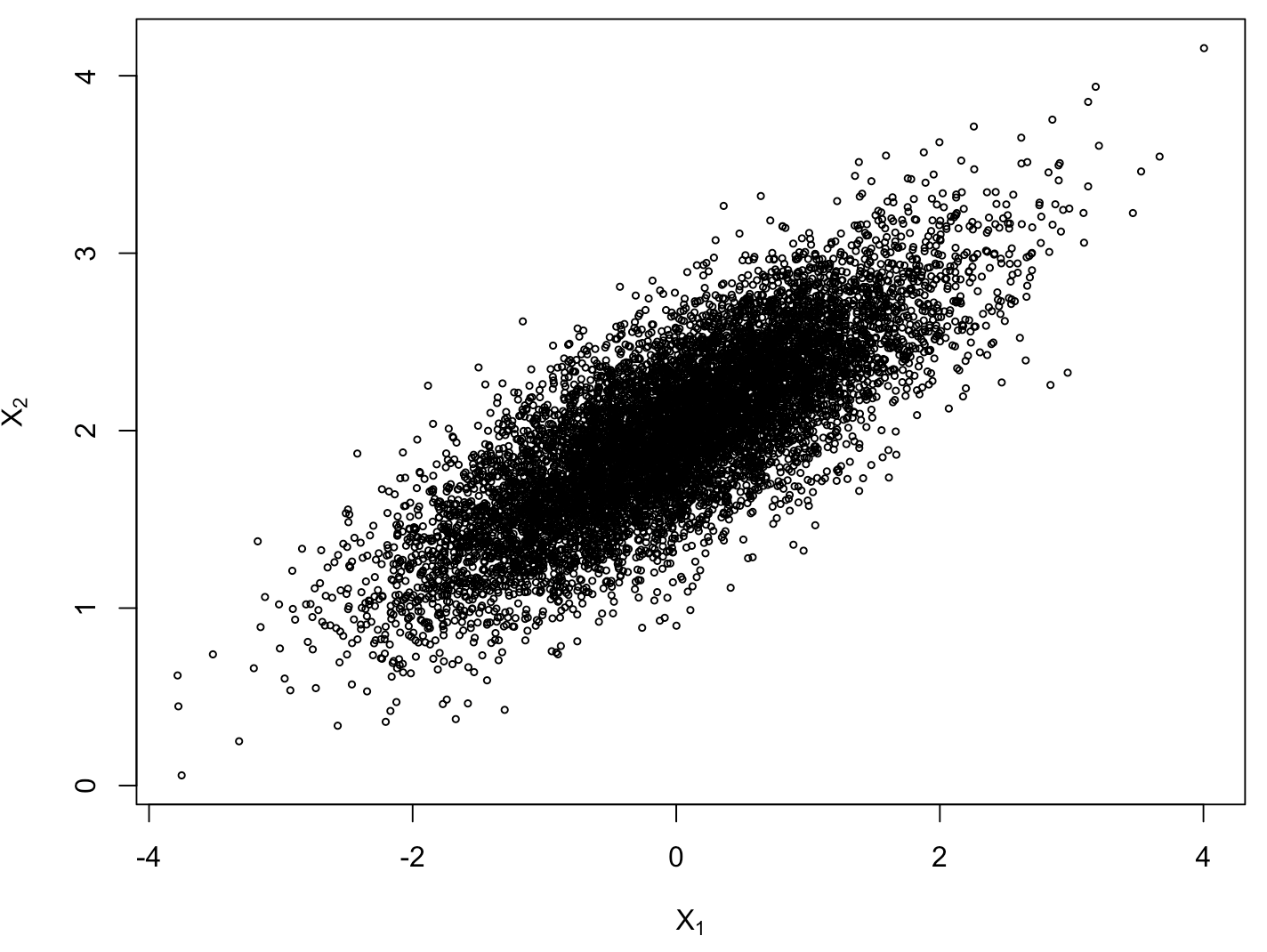
plot(x[,1], x[,2])
colMeans(x)
## [1] -0.01153641 1.99839723
cov(x)
## [,1] [,2]
## [1,] 0.9664485 0.3850833
## [2,] 0.3850833 0.2431846
cor(x)
## [,1] [,2]
## [1,] 1.0000000 0.7943231
## [2,] 0.7943231 1.0000000
可以看到,模拟的数值与真值十分接近。
下面介绍切片Gibbs抽样方法。切片Gibbs抽样方法主要用于Gibb采样中完全的条件分布没有简单或者方便的形式的情形。这个方法通过添加一些辅助变量把参数空间扩大,但保持感兴趣的边际分布不变,而把所有的条件分布转变成标准形式,然后就可以使用标准的Gibbs抽样方法。
考虑目标分布 $g(x)$,它很难进行抽样。引入新的辅助变量 $u$,其条件分布为 $f(u\mid x)$,则联合分布为
而 $x$ 的边际分布等于目标分布 $g(x)$。因此可以使用Gibbs算法从联合分布 $f(u,x)$ 以及边际分布 $f(u)$ 和 $f(x)=g(x)$ 中产生随机数:
- 产生 $u\sim f(u\mid x)$;
- 产生 $x\sim f(u\mid x)g(x)$。
条件分布 $f(u\mid x)$ 常用的一个选择是均匀分布 $U(0,g(x))$,此时
因此,此时Gibbs抽样算法如下:
- 产生 $u^{(t)}\sim U(0,g(x^{(t-1)})$;
- 产生 $x^{(t)}\sim U(x:0\leq u^{(t)}\leq g(x))$。
在大部分情况下,辅助变量的选择是“自然的”,参见下面这个例子。
设样本 $X_1,\dots,X_n$ 来自混合密度 $f(x)=\sum\limits_{k=1}^K\pi_k\phi_{(\mu_k,1/\tau)}(x)$,其中 $K,\tau$ 已知,$\phi$ 为正态密度函数。设 $(\pi_1,\dots,\pi_K)\sim\mathcal D(\alpha_1,\dots,\alpha_K)$,$\mu_1,\dots,\mu_K$ i.i.d. $\sim N(\mu_0,1/\tau_0)$,要求参数 $\pi_1,\dots,\pi_K$ 和 $\mu_1,\dots,\mu_K$。
首先容易写出后验密度
显然全条件密度不容易抽样,引入辅助变量 $Z_1,\dots,Z_n$ 表示每个观测来自的总体标签,即
此时联合密度函数为
因此
进一步可计算得
因此,Gibbs算法如下:
选取初始值 $\pmb\mu^{(0)}$,$\pmb\pi^{(0)}$,迭代 $t=1,2,\dots,T$:
- 对 $i=1,\dots,n$,从离散分布
$\mathbb P(Z_i^{(t)}=k)=\dfrac{\pi_k^{(t-1)}\phi_{(\mu_k^{(t-1)},1/\tau)}(x_i)}{\sum_{l=1}^K\pi_l^{(t-1)}\phi_{(\mu_l^{(t-1)},1/\tau)}(x_i)},\quad k=1,\dots,K$ 中抽取 $Z_i^{(t)}$。
- 对 $k=1,\dots,K$,抽取
$\mu_k^{(t)}\sim N\left(\dfrac{\tau\sum\limits_{i:Z_i^{(t)}=k}x_i+\tau_0\mu_0}{\sharp\{i:Z_i^{(t)}=k\}\tau+\tau_0},\dfrac{1}{\sharp\{i:Z_i^{(t)}=k\}\tau+\tau_0}\right).$ - 抽取
$\pmb\pi^{(t)}\sim\mathcal D\left(\alpha_1+\sharp\{i:Z_i^{(t)}=1\},\dots,\alpha_K+\sharp\{i:Z_i^{(t)}=K\}\right).$
Hamiltonian蒙特卡洛
Hamiltonian/Hybrid Monte Carlo(HMC)是一种MCMC方法,它采用物理系统动力学而不是概率分布来产生马尔可夫链的未来状态提议值。这使马尔可夫链可以更有效地探索目标分布,从而加快收敛速度。
在一个哈密顿系统中,我们考虑一个物体在时刻 $t$ 处于位置 $\pmb x$ 且具有动量(或速度)$\pmb v$。此时系统总能量为 $H(\pmb x,\pmb v)=U(\pmb x)+K(\pmb v)$,其中 $U$ 为势能,$K$ 为动能。这类系统满足以下哈密顿方程组(描述动能和势能的转换):
因此当我们有了两个微分表达式以及一组初始条件,则有可能通过模拟系统在时长 $T$ 内的演变来预测物体在 $t=t_0+T$ 时刻的位置和动量。
为了在计算机上数值模拟哈密顿动力学,必须通过离散化时间来近似哈密顿方程。我们将时长 $T$ 分成一系列较小的长度为 $\delta$ 的间隔,下面介绍Leap Frog方法:
- 首先使用Taylor展开,计算 $v_i(t+\delta/2)=v_i(t)-(\delta/2)\dfrac{\partial U(\pmb x)}{\partial x_i(t)}$;
- 更新位置 $x_i(t+\delta)=x_i(t)+\delta\dfrac{\partial K(\pmb v)}{\partial v_i(t+\delta/2)}$;
- 更新动量 $v_i(t+\delta)=v_i(t+\delta/2)-(\delta/2)\dfrac{\partial U(\pmb x)}{\partial x_i(t+\delta)}$。
Hamiltonian蒙特卡洛的主要思想是构造哈密顿函数 $H(\pmb x,\pmb v)$,使用统计力学的规范分布概念将 $H(\pmb x,\pmb v)$ 与 $p(\pmb x)$ 关联起来非常容易:
从而可以使用哈密顿动力学对 $\pmb x$ 和 $\pmb v$ 的联合分布进行抽样。
对于 $\pmb v$,正态分布是一种常用的分布选取:
而对于 $\pmb x$,给定目标分布 $p(\pmb x)$,则可以定义
如果偏导数 $\partial U(\pmb X)/\partial x_i$ 可以得到,则可以使用上述Leap Frog算法进行模拟。具体算法如下:
- 令 $t=0$,产生初始位置 $\pmb x^{(0)}\sim\pi^{(0)}$。
- 重复 $t=1,2,\dots,T$:
- 令 $t=t+1$,产生一个新的动量 $\pmb v_0\sim p(\pmb v)$;
- 令 $\pmb x_0=\pmb x^{(t-1)}$;
- 使用Leap Frog算法,从 $(\pmb x_0,\pmb v_0)$ 出发,时长 $L$ 和步长 $\delta$,得到 $\pmb x^\star,\pmb v^\star$;
- 计算接受概率
$\alpha=\min\{1,\exp(-U(\pmb x^\star)+U(\pmb x_0)-K(\pmb v^\star)+K(\pmb v_0))\}.$ - 以概率 $\alpha$ 接受 $\pmb x^{(t)}=\pmb x^\star$,否则 $\pmb x^{(t)}=\pmb x^{(t-1)}$。
HMC方法实施中需要指定多余参数 $L,\delta$ 的值。相比于M-H算法,HMC方法:
- 连续生成的两个状态之间的距离一般比较大,因此抽取代表性样本所需迭代次数较少;
- 单次迭代的成本较高(需要模拟哈密顿动力学过程),但是仍然显著地更有效;
- 大部分情况下会接受新状态;
- 当分布有分开的局部最小值时无法进行全部抽样,可以考虑不同初始值。
后记
本文内容参考自中国科学技术大学《贝叶斯分析》(2022Fall)课件。
如对本文内容有任何疑问,请联系 watthu@mail.ustc.edu.cn。